Software Design Patterns
Florian Rappl, Fakultät für Physik, Universität Regensburg
Software Design Patterns
Introduction to modern software architecture

Best practices
Introduction
- In this section best practices will be shown for:
- object-oriented design,
- code transformations (refactoring),
- robustness (test driven development),
- performance (device independent) and
- readability.
- The content is complementary to the previous chapters
Levels of design
- Creating software is much more than just programming
- A lot of time needs to be taken for designing an application
- There are various levels of architecture:
- System
- Packages (e.g. business rules, UI, DB, dependencies on the system)
- Classes
- Routines
- Logic / algorithm
Desirable characteristics of a design
- Minimal complexity
- Ease of maintenance
- Loose coupling (good abstraction, information hiding)
- Extensibility and reusability
- High fan-in (large number of classes that use a given class)
- Low fan-out (a given class should not use too many other classes)
- Portability
- Leanness, i.e. no extra parts, backward-compatible
- Stratification: The system must be consistent at any level
Defensive programming
- Protecting from invalid input
- Unit testing
- Error-handling (e.g. return neutral value, error code, same answer as last time, ...)
- Robustness and correctness
- Exceptions are introduced if wrong inputs happen
- Being not too defensive is key (remove trivial error checking from production code, ...)
Common errors
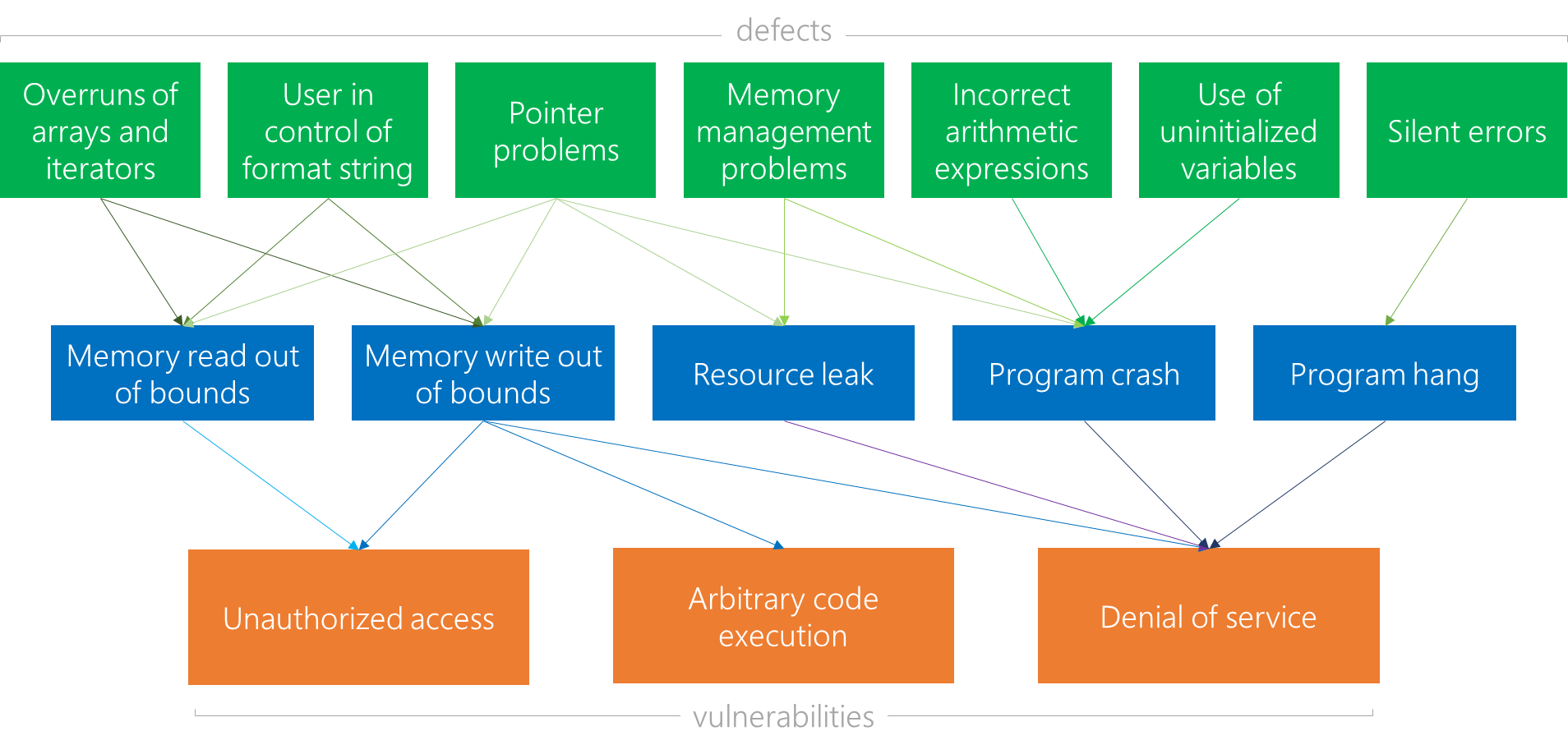
Test-driven development
- How to ensure that software is robust? We need tests!
- But software complexity usually grows exponentially
- TDD tries to give us a plan for automated tests
- In the end our software is able to inform us about bugs before we experience them by running the application
- The basic concept is to get some rapid feedback during development
- The risk of change is controlled by having a sufficient number of tests
- We are able to detect problems in the specification
TDD cycle
- A TDD cycle consists of three phases
- Red
- Green
- Refactor
- In the first phase we ensure that everything is compiling, but the test is failing (since the method just returns a dummy value)
- Now we try to create an implementation that makes the test succeed
- In the third phase we improve the implementation of the method
- Any scenario that needs to be covered by the method has to be tested
TDD cycle
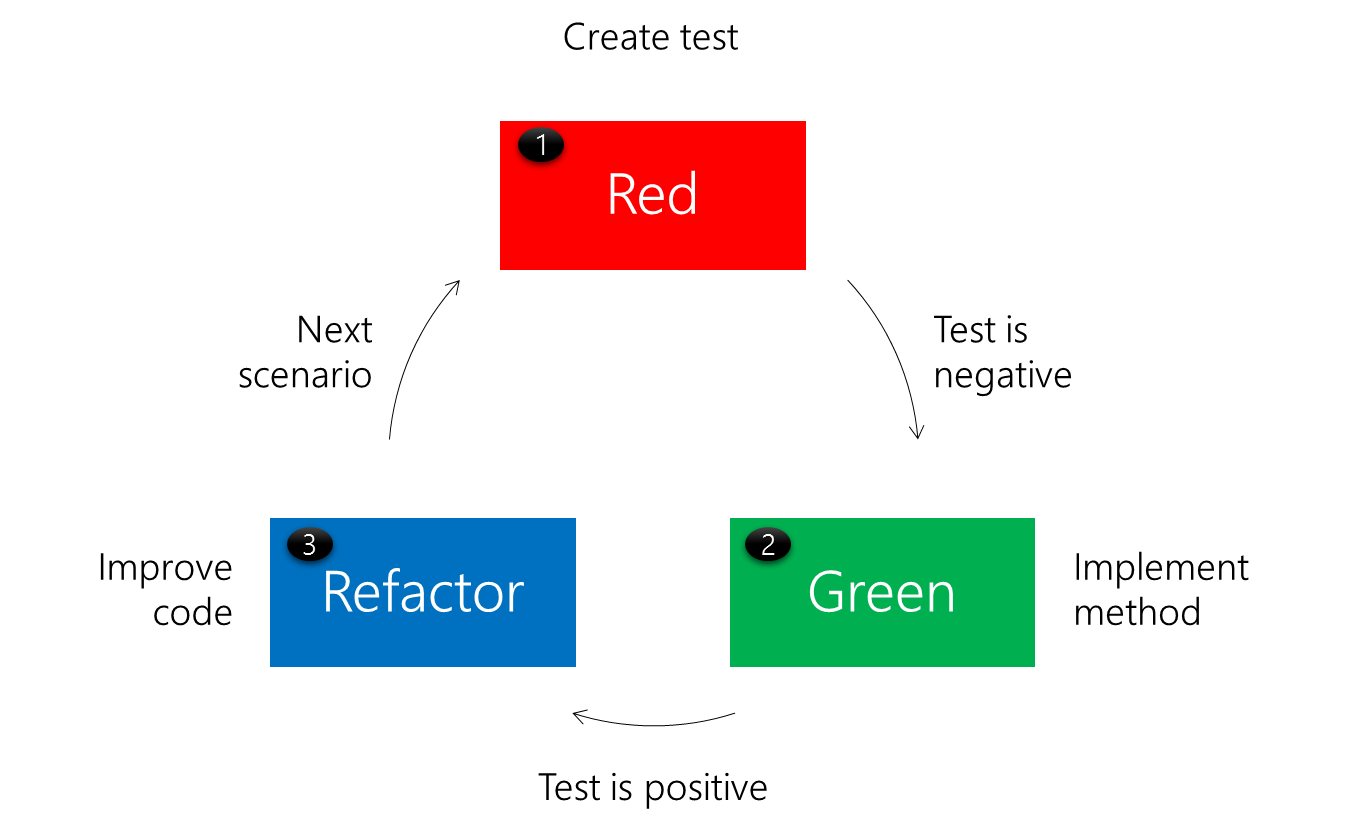
Red-Green-Refactor
- The red phase is key, since it tries to ensure that the test is bug-free
- One should first see the test failing (if it should) before succeeding
- So overall the process is
- Add a test and run all tests (new one should fail)
- Implement the method and run all tests (should be green now)
- Refactor code and repeat the test (should still be green)
- The test itself should be as simple as possible
- No logic, and following a certain pattern
Test structure
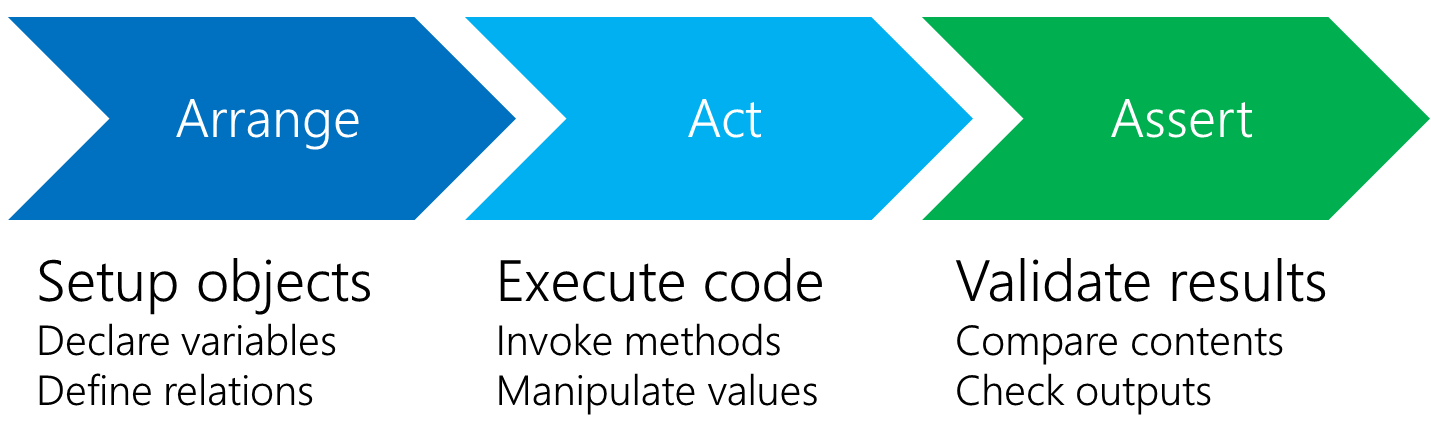
Remarks
- Every test consists of creating a test class, performing some setup, invoking the test method and a final cleanup step
- TDD is an important part of any agile development process
- The KISS (Keep It Simple Stupid) and YAGNI (You Aren't Gonna Need It) principles are usually followed
- This means that small, extensible units are build that only have one responsibility
- The focus lies on the desired job (project goal)
Shortcomings
- UI, any external resources (databases, filesystems, network, ...) and others are hard to test (require functional tests)
- Writing tests is time-consuming
- Blind spots are more likely if writing the tests is not delegated
- Integration and compliance testing might be reduced due to a false sense of security
- The tests need to be maintained as well
- Big changes in the architecture might result in a time-consuming update of all tests
Code refactoring
- In short, refactoring is a
disciplined technique for restructuring an existing body of code, altering its internal structure without changing its external behavior.
- Therefore refactoring should improve code readability by reducing complexity
- Also the code should be made maintenance friendly, yet extensible
Refactoring strategies
- Refactor when adding a routine
- Refactor when adding a class
- Refactor when fixing a bug
- Target error-prone modules
- Target high-complexity modules
- Improve the parts that are touched
- Define an interface between clean and ugly code
Reasons to refactor (1)
- Code is duplicated
- Routine is loo long
- A loop is too long or too deeply nested
- A class has poor cohesion
- A class interface does not provide a consistent level of abstraction
- A parameter list has too many parameters
- Changes within a class tend to be compartmentalized
- Changes require parallel modifications to multiple classes
Reasons to refactor (2)
- Inheritance hierarchies have to be modified in parallel
- Case statements have to be modified in parallel
- Related data items that are used together are not organized into classes
- A routine uses more features of another class than its own class
- A primitive data type is overloaded
- A class doesn't do very much
- A chain of routines passes tramp data
- A middleman object isn't doing anything
Reasons to refactor (3)
- One class is overly intimate with another
- A routine has a poor name
- Data members are public
- A subclass uses only a small percentage of its parents' routines
- Comments are used to explain difficult code
- Global variables are used
- A routine uses setup code before a routine call or takedown code after a routine call
Kinds of refactorings
- Data-Level (e.g. hide class fields)
- Statement-Level (e.g. simplify ifs)
- Routine-Level (e.g. extract method)
- Class implementation (e.g. value to reference)
- Class interface (e.g. SRP)
- System-Level (e.g. factory pattern)
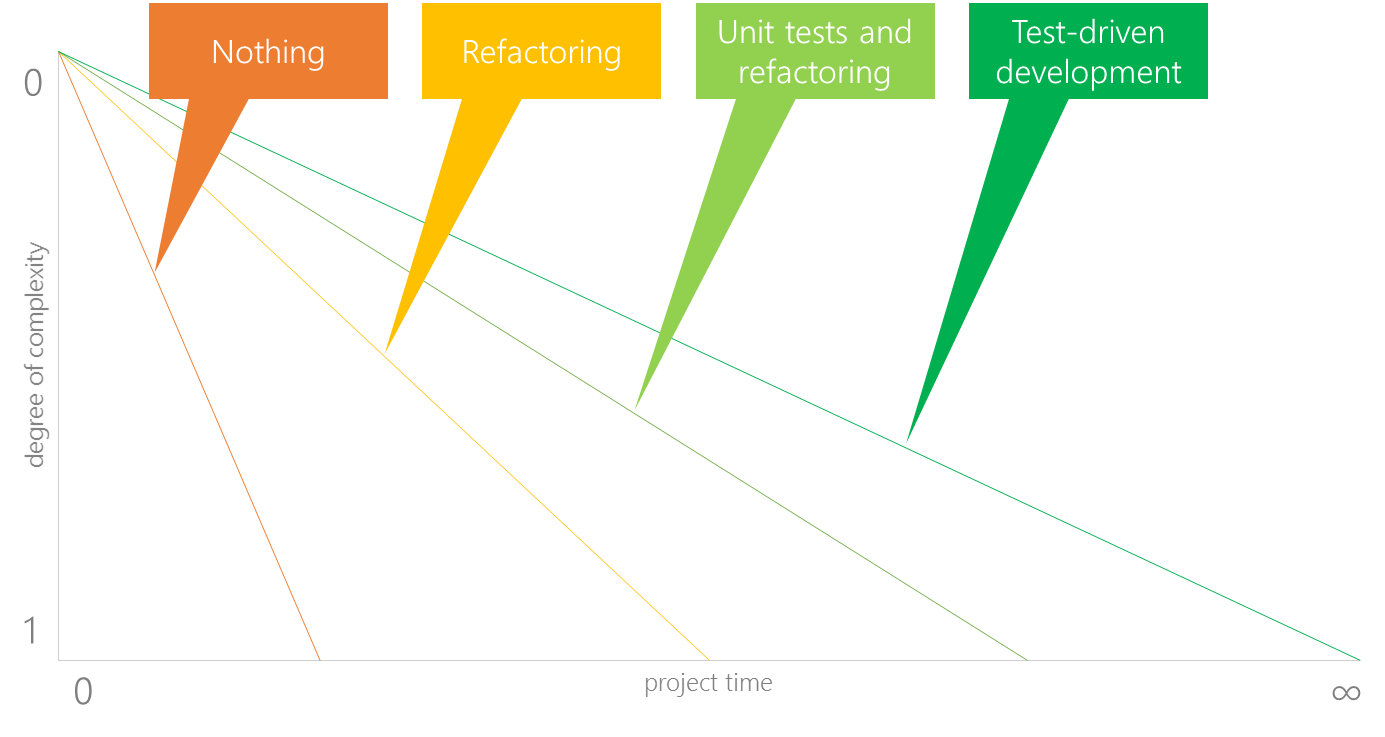
Refactoring and TDD
Data-Level refactorings
- Replace a magic number with a named constant
- Rename a variable with a clearer or more informative name
- Move an expression inline or replace an expression with a routine
- Introduce an intermediate variable
- Convert a multi-use variable to multiple single-use variables
- Use a local variable for local purposes rather than a parameter
- Convert a data primitive to a class
- Convert a set of type codes to a class or an enumeration
- Change an array to an object / encapsulate a collection
Statement-Level refactorings
- Decompose a Boolean expression
- Move a complex Boolean expression into a well-named Boolean function
- Consolidate fragments that are duplicated within different parts of a conditional
- Use break or return instead of a loop control variable
- Return as soon as you know the answer instead of assigning a return value within nested if-then-else statements
- Replace conditionals with polymorphism
- Create and use null objects instead of testing for null values
Routine-Level refactorings
- Extract routine / extract method
- Move a routine's code inline
- Convert a long routine to a class
- Substitute a simple algorithm for a complex algorithm
- Add or remove a parameter
- Separate query operations from modification operations
- Combine similar routines by parametrization
- Separate routines whose behavior depends on parameters passed in
- Pass a whole object rather than specific fields or vice versa
Class implementation refactorings
- Change value objects to reference objects
- Change reference objects to value objects
- Replace virtual routines with data initialization
- Change member routine or data placement
- Extract specialized code into a subclass
- Combine similar code into a superclass
Class interface refactorings
- Move a routine to another class
- Convert one class to two or vice versa
- Hide a delegate or remove a middleman
- Replace inheritance with delegation or vice versa
- Introduce a foreign routine or extension class
- Encapsulate an exposed member variable
- Hide routines that are not supposed to be used outside the class
- Collapse a superclass and subclass if their implementations are very similar
System-Level refactorings
- Create a defined reference source for data that is beyond our control
- Change unidirectional class associations to bidirectional class associations
- Change bidirectional class associations to unidirectional class associations
- Provide a factory method rather than a simple constructor
- Replace error codes with exceptions or vice versa
About subroutines
- Historically two kind of operations have been established:
- A function (does some computation and returns the result)
- A procedure (modifies something and has no result)
- Now we mostly talk about methods (implemented operations of a class)
- There are several questions concerning these operations and their parameters
- Specifically when to extract methods, how to name them and how to structure output and input parameters
Why another routine?
- Reduce complexity
- Avoid duplicate code
- Support subclassing
- Hide sequences or pointer operations
- Improve portability
- Simplify complicated boolean tests
- Improve performance
- However: NOT to ensure that all routines are small!
Naming routines
- Describe what the routine does
- Avoid meaningless verbs
- Don't use numbers for differentiation
- Make routine names as long as necessary (for variables 9-15 chars)
- For a procedure: Use a strong verb followed by an object
- For a function: Use a description of the return value
- Otherwise use opposites precisely (open/close, add/remove, create/destroy)
- Establish connections
Routine parameters
- Parameters should always be as general as possible
- The opposite is the type of the return value
- This type should be as specific as possible
- We call incoming parameters contra-variant
- Outgoing parameters (return values) are co-variant
- Such a style increases flexibility by allowing methods to be used with more types
- Also the return value is then a lot more useful
Using parameters
- Follow the order: Input-Modify-Output
- Consider creating own input and output keywords if possible
- Otherwise create or use conventions like in*, out* for names
- Use all parameters
- Put status or error variables last
- Don't use routine parameters as working variables
- Limit routine parameters to max. 7
- Use named parameters if possible
Code optimization
- Not trivial, since code should be readable and follow our conventions
- Nevertheless sometimes parts of the application are performance critical
- Problem: Most optimizations should have been integrated in the design
- But "premature performance optimization is the root of all evil"
- Only solution: Try to maximize performance and change design if still not good enough
Performance analysis
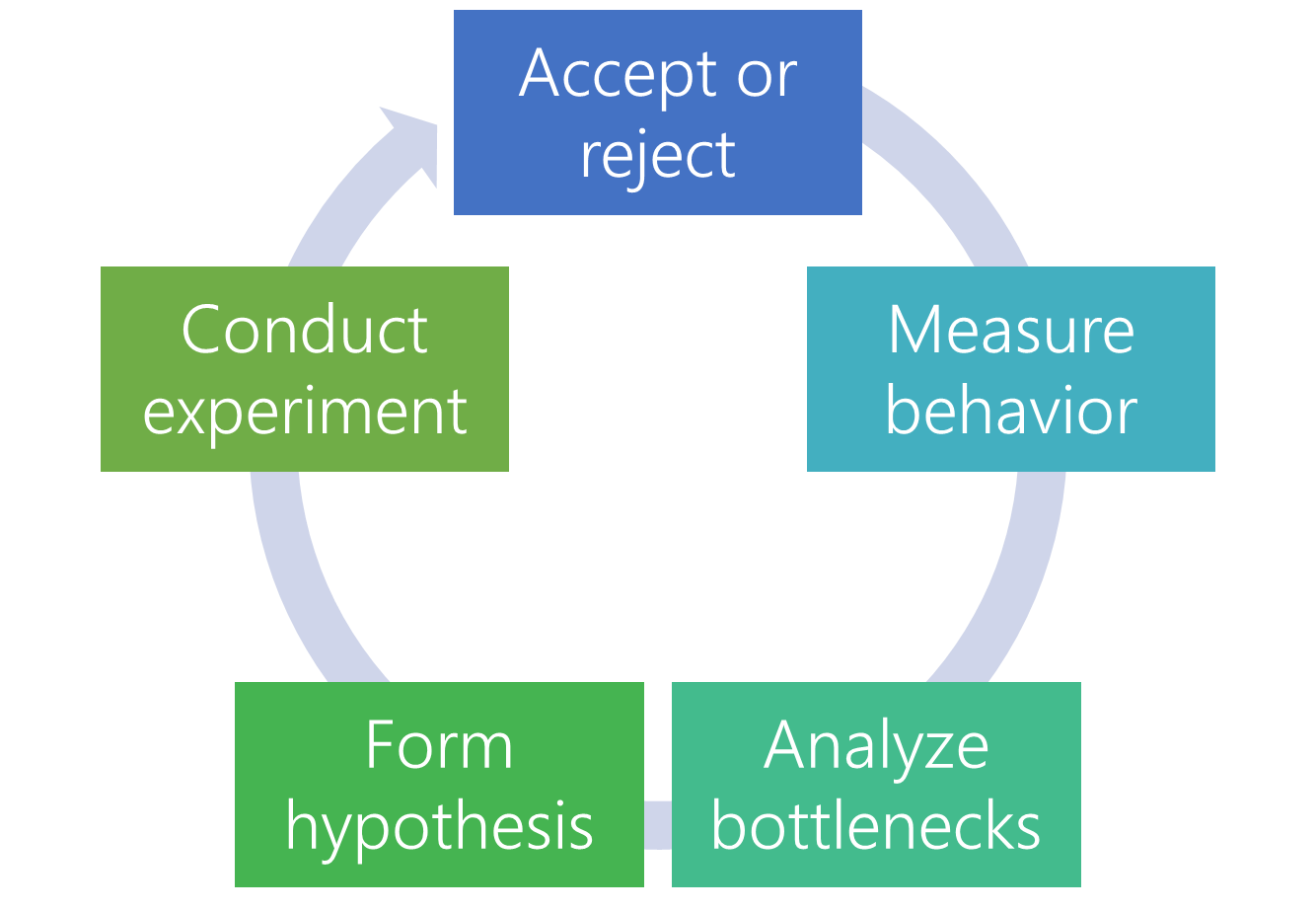
Common techniques
- Substitute table lookups for complicated logic
- Jam loops
- Use integer instead of floating point variables when possible
- Initialize data at compile time
- Use constants of the correct type
- Precompute results
- Eliminate common subexpressions
- Translate key routines to a low-level language
Quick improvements (1)
- Order tests (switch-case, if-else) by frequency
- Compare performance of similar logic structures
- Use lazy evaluation
- Unswitch loops that contain if tests
- Unroll loops
- Minimize work performed in loops
- Put the busiest loop on the inside of nested loops
Quick improvements (2)
- Change multi-dimensional to one-dimensional array
- Minimize array references
- Augment data types with indices
- Cache frequently used variables
- Exploit algebraic identities
- Reduce strength in logical and mathematical expressions
- Rewrite routines inline
Literature
- McConnell, Steve (2004). Design in Construction.
- Sedgewick, Robert (1984). Algorithms.
- Kerievsky, Joshua (2004). Refactoring to Patterns.
- Fowler, Martin (1999). Refactoring: Improving the design of existing code.
- Weisfeld, Matt (2004). The Object-Oriented Thought Process.
- Beck, Kent (2003). Test-Driven Development by Example.